In the age of Big Data, raw data is often disorganized and stored in disparate systems. While these bits of data are separated, their value is largely inaccessible to the companies that own it and their data specialists. In rare cases, this “silo” effect results in that data’s value being entirely lost.
In 2018, Microsoft launched a data integration tool fully hosted in the Cloud as Azure Data Factory. This tool allows companies to orchestrate and consolidate the raw data from these systems to make them consumable by data specialists. This article explores this tool’s capabilities, limitations and its ideal use cases.
Microsoft’s strategy has seen it follow a cloud computing approach in the past few years with the launching of several services within the Azure cloud ecosystem to encourage companies to innovate and get value from their data assets. The main advantage of the Azure platform is that it brings together multiple functionalities and tools under one global data management platform. This is a platform similar to SSIS (SQL Server Integration Services), which Microsoft aim to replace gradually. Azure Data Factory, in particular, is a leading solution for building hybrid extraction-transformation-loading (ETL) or extraction-loading-transformation (ELT) and data integration pipelines.
This service enables companies to reduce the use of physical or virtual machines to process their data. The main objective of this new feature is to limit maintenance, costs of maintenance, and software installations. We always maintain the option to process, transform, store, delete and archive data using SSIS and Azure storage spaces.
What does Azure Data Factory do?
Azure Data Factory allows data engineers to integrate data from a variety of local, cloud-based, structured, and unstructured sources. It also allows companies to connect to several different data sources as well as data processing services. These sources and services include – but are not limited to – a multitude of Azure services, several different database types, REST APIs, Salesforce, Dynamics CRM, and Jira. The ultimate goal is to then move this data into a common repository. Azure Data Factory’s makes easy work of building these types of automated data pipelines and is particularly easy for data engineers to adopt with little experience. This allows companies within the Azure platform to build the data infrastructure required to centralize their data efficiently with the aim of achieving a quick return on investment.
Once this data has been centralized in one location, one can also use Azure Data Factory to process and transform that collected data using the mapping data flow, a feature which allows engineers to efficiently develop data transformation logic “code-free”. Additionally, Azure Data Factory also allows one to input code manually to create custom transformations. Data transformations can also be executed on computing services such as HDInsight Hadoop, Data Lake Analytics, Spark and Machine Learning.
Lastly, once the data has been ingested, stored and transformed, engineers can use Azure Data Factory to publish that data. This tool fully supports CI/CD (continuous integration/continuous delivery) of pipelines through Azure Devops, while also allowing for the possibility of a Github integration for improved version control. This allows for the efficient creation and development of more complex ETL processes. Azure Data Factory is one of the best solutions to use when it comes to building ETL or ELT pipelines in the cloud due to the simplicity with which such pipelines can be configured.
One of the major advantages to Azure Data Factory is that it is easily accessible and incorporated with other Azure Compute & Storage resources. One can easily define linked services including Azure SQL Database, Azure SQL Data Warehouse, a Data Lake, a file system, and NoSQL databases. Furthermore, one may use pipeline activities to modify and enrich the data, such as Azure HDInsight, Azure Machine Learning, stored procedures from any SQL database, U-SQL Data Lake Analytics activity, Azure Databricks, and many more.
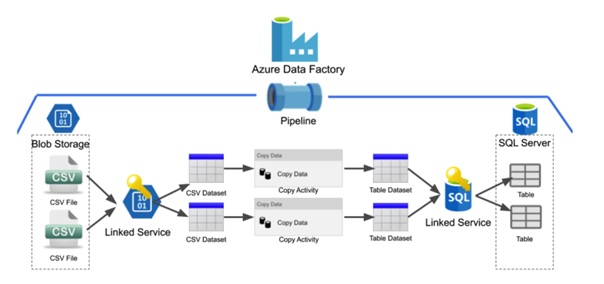
Today the use of software such as Azure Data Factory is essential to manage large volumes of data. Big Data solutions greatly support a company’s ability to manage and control its activities. This means that one’s data quality must be impeccable. We believe that Azure Data Factory can play a huge role in accelerating an organization’s journey towards being truly data-driven thanks to its ease of use, cost-efficiency and flexible functionality.
If you would like to make use of Azure Data Factory or are interested in finding out whether it’s suitable to your existing business needs, contact us at info@imovo.com to schedule a call with one of our data experts. If you are interested in learning more about data engineering on Azure, you may also book a place at our Data Engineering 101 course.